
Figma
Figma is a collaborative UI design tool for creating beautiful interfaces and prototypes.
We partner with startups, scaleups, and visionary businesses to build fast, intelligent, and scalable software solutions. Our engineers bring the speed, precision, and technical edge needed to deliver market-ready products that meet the highest standards — built to scale, built to last.

Trusted By
A line of startup and business we are working with including our products





Welcome to Algorithm – an end-to-end development company providing full-cycle software development services to businesses of varying sizes and across diverse industries, including Healthcare, FinTech, SaaS, EdTech, AI, and more.




Figma is a collaborative UI design tool for creating beautiful interfaces and prototypes.
We combine next-gen AI capabilities with our proven track record to catapult your business to new heights

Medlens AI is a clinical assistant that interprets diagnostic reports and calculates risk scores to support faster, smarter medical decisions.
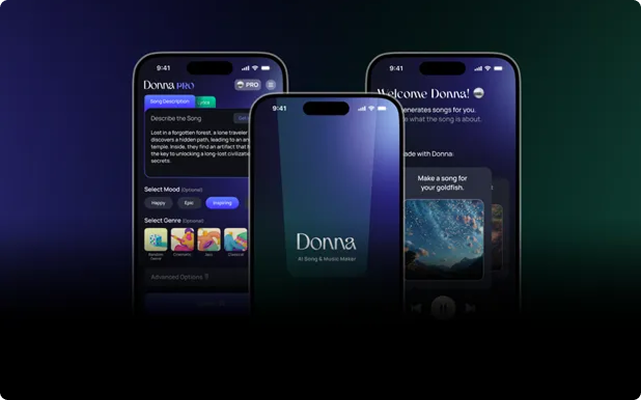
Donna AI: Your 24/7 AI receptionist that books appointments and qualifies leads with human-like conversations.
We combine next-gen AI capabilities with our proven track record to catapult your business to new heights
Every great product starts with a vision. We collaborate with you to understand what you want to build and how we can drive growth to give you a competitive edge.
Key Steps in This Phase:

Once we understand your goals, we move fast to build a team with the exact skills required. You'll receive curated developer profiles for review — all within 48 hours.
Key Steps in This Phase:

With a clear roadmap in place, we swiftly begin development. In as little as two weeks, your remote team is onboarded and ready to start turning your ideas into high-quality, scalable software.
Key Steps in This Phase:

Whether you need to ramp up or scale down, our flexible engagement model grows with you — ensuring you have the right support at every stage of your journey.
Key Benefits of Our Mode:

Talented Team!
Full Scale Projects Delivered
Years of Experience
World Class Engineers
Happy Clients :)
Domains We Work In
Transforming Industries with Cutting-Edge Solutions
We design products that don't just look good — they feel right. Our UI/UX design process puts your users at the center of every decision.
We build robust, scalable web applications using modern frontend and backend technologies—delivering secure, high-performance solutions tailored to your business needs.
From concept to launch, we design and develop mobile apps that deliver seamless experiences across all devices and platforms.
Need to scale your tech team? We provide dedicated developers who work as an extension of your business — fully aligned with your goals.
Once development is complete, we ensure your product works flawlessly through thorough testing and validation — before it reaches your users.
We help you turn data into intelligence. From smart features to full-scale AI products, we turn your vision into machine-powered solutions.
Deliver faster with our DevOps solutions. We automate, integrate, and optimize your workflows so your apps move at the speed of your business.
We tailor solutions to your unique needs—whether you're a Enterprises, SME, or startup
Solutions Engineered for Scale
We help large enterprises thrive in the digital landscape by combining speed with excellence:

Partnering for Rapid Innovation and Sustainable Growth
We fuel startups with lean, high-impact tech solutions – built to scale fast without breaking the bank:

Accelerating Growth Through Technology
We empower SMEs to compete digitally—delivering enterprise-grade quality at startup speed:

Whether we work with startups, established organizations, or enterprises, Algorithm follows agile methodologies used by the fastest software companies in the world. We bring to your business the latest technologies, innovative ideas, and software development practices. Our clients access our product development experience, which allows them to avoid typical software development pitfalls.
Testimonials
A few words from our satisfied clients as they share their success stories with us

 Faisal Tahir 3 min read
Faisal Tahir 3 min read How to Test a Bug Fix the Right Way: Beyond “It’s Working Now” Most people think testing a bug fix is simple: Find the bug → Developer fixes it → You recheck → Done. But that approach only scratches the surface. If you want to become an effective tester, someone who adds real value to the development cycle, you have to go deeper than just verifying that “it works now.” You need to understand what went wrong, why it went wrong, and what was changed to fix it. That’s where root cause awareness becomes the game changer. Typical Flow of a Bug Fix Here’s what usually happens in a fast-paced team: QA reports a bug. The dev takes ownership, makes a fix, and moves the ticket to “Fixed.” QA gets it back with no note on the root cause, no mention of what changed, and no explanation of potential side effects. Now QA retests using the same steps that originally caused the bug. It passes. So the tester closes it. Everything seems fine until two sprints later when a similar bug reappears elsewhere in the system. The Real Problem When you don’t know the root cause, you’re not really testing the fix — you’re just re-testing the symptom. Without knowing what was changed in the code or logic: You can’t identify regression risks. You don’t know what related modules might be impacted. You can’t design effective test cases for validation. You might verify that the specific error doesn’t show up again — but you can’t guarantee that nothing else broke in the process. A Real Example Imagine this: An API returns HTTP 500 for one user. All other users get the correct response. The bug is fixed, and QA retests with the same user — the error is gone. Test passed. But after discussing with the developer, you learn: “The error occurred only for users with a system history longer than 20 months.” That one detail changes everything. Now, as a good tester, you expand your testing scope to include: A fresh user (0 months history) A user with exactly 20 months of history A user with 21 months A user with 40 months And the user with the longest recorded history in the system You’re no longer just testing “if it works now”, you’re testing how robust the fix is and whether it scales or regresses under edge cases. Why This Matters The difference between an average tester and a great tester is the ability to turn developer feedback into testing insights. Every conversation with a developer can uncover: New risk areas Code dependencies Logic paths you didn’t know existed Data combinations that can break under real conditions When you understand the root cause, you’re better equipped to: Identify similar vulnerabilities elsewhere in the product Suggest preventive checks or assertions Strengthen regression coverage for future builds Testing without context is like shooting in the dark, you might hit the target, but you won’t know why you missed next time. The Best Practice Next time you pick up a “Fixed” ticket, don’t just retest the bug. Ask the developer: What was the root cause? What part of the code or logic was changed? What was the scope of impact? It’s not about micromanaging or questioning, it’s about aligning on quality ownership. The goal is not just to close bugs, it’s to reduce the probability of their recurrence and improve system reliability. Final Thought As testers, our job is not just to confirm functionality. It’s to understand behavior, risk, and stability. When you combine developer insight with test creativity, you transform QA from being a reactive process into a proactive safeguard for the product. The next time you test a fix, remember: “Understanding the root cause gives you the power to test smarter, not harder.” Because great testing doesn’t just find bugs, it prevents the next ones.

 Saad Rahman 3 min read
Saad Rahman 3 min read When optimizing a landing page I built with Next.js, my goal was simple. push the performance score as high as possible. Next.js already handles a lot under the hood such as code splitting, image optimization, and lazy loading, but true performance gains often come from attention to detail. Here are a few lessons that made the biggest difference: 1. Think About Performance from Day One Performance isn’t an afterthought. Fixing it at the end can be painful. Building with optimization in mind from the start saves hours of debugging later. You can regularly check your site’s speed using Lighthouse (in Chrome DevTools) or Google PageSpeed Insights. They measure key metrics like: TTL (Time to Load): How long it takes for your page to fully load. LCP (Largest Contentful Paint): How quickly the main content (like a hero image or headline) appears. FID (First Input Delay): How fast the page responds when a user interacts for the first time. CLS (Cumulative Layout Shift): How stable the layout is while loading. Keeping these metrics in check ensures your page not only loads fast but also feels fast. 2. Use Modern Image Formats Prefer .webp over .png or .jpg. WebP images are typically 25–35% smaller while maintaining the same visual quality, helping browsers render content faster and use less bandwidth. You can convert your images to WebP using Squoosh, a free tool that allows you to compress, preview, and export optimized images easily. 3. Match Image Resolution to Usage I initially made the mistake of using a 400×400 image inside a 50×50 container, which slowed things down unnecessarily. Scaling large images in the browser increases load time and wastes resources. Make sure your images match their actual display size. Tools like Squoosh can also resize your images before exporting so you serve only what’s needed. 4. Use Separate Images for Mobile and Desktop Large desktop images can hurt performance on mobile. A 2000px-wide hero image might look great on desktop but will slow down smaller screens. To fix this, use responsive images with the Next.js <Image> component and define multiple image sizes using the sizes or srcSet attributes. This ensures each device only downloads the image it needs. You can also use Squoosh to create two versions of each image, one optimized for desktop and another for mobile, both in .webp format. 5. Test Production Builds, Not Dev Lighthouse scores can vary widely between development and production. My score jumped from under 80% in development to above 95% once I tested the production build. There are two main ways to run a production build locally: Option A: Run the Next.js production server (for SSR/ISR sites) Option B: Export a static site and serve it locally App Router (Next 13+): Then: Note: Static exports do not support SSR, API routes, or on-demand rendering. Use this only for fully static pages. Conclusion When building fast and efficient web pages with Next.js, keep the following in mind: Measure performance early and often using Lighthouse or PageSpeed Insights. Optimize images with modern formats like .webp. Always match image resolution to its display size. Use separate images for mobile and desktop to avoid unnecessary downloads. Test production builds rather than relying on development mode. Keep an eye on key metrics such as LCP, FID, and CLS for a smoother user experience. Build with efficiency in mind from the start rather than treating performance as an afterthought.

 Muhammad Uzair 3 min read
Muhammad Uzair 3 min read Do you overthink making your yet-to-be-made app scalable? Great, you're not the only one, but should you? Here are some scalability stories from the famous tech that you use every day. Hope you'll find them insightful. 1) Facebook As Facebook started as a little Stanford project and then started scaling the university campus-wise. Do you know how they used to do that? Facebook used to have a separate server for each campus with each having its own code, MySql database, and memecache. Each time FB need to have another campus they would install a new server with its own server, code, and database. Each user was restricted to its own campus, they would have a weird "harvard.facebook.com" type URL for each user. Later when they decided to let different campus users talk to each other, it took them a year to come up with an efficient so-called single-global-table, where users can add each other globally. 2) Gmail yeah I mean the defacto standard for emails, Gmail. Do you how it was initiated & scaled? A guy name Paul Buchheit from google didn't like to use existing email clients because he wasn't satisfied with their UI. So he hacked together a little tool to just preview his emails in google groups UI & he liked it. Then he started adding little new features when he feel like it should have something else, like let's add a writing emails option, a delete button... One day he showed his created little email client to his co-worker and he kinda likes it, but the problem was he wasn't able to use his email in it because Paul's email was hardcoded in it. Paul just realized he should make it flexible to allow for other emails to be used instead of his one. People start to use it inside google, a day it went down & someone came to Paul and said, do you know Gmail has been down since morning. He said no, I was busy with work didn't know that :D 3) Twitch Initially, video streaming cost was very high when twitch started, every little detail on their web page will fire a query to get data, e.g watch count, likes count, etc They decided to cut the cost by loading all website data in cache except video and chat. Therefore video was played but none of the buttons was interactive except chat. All those data were being loaded from local storage. Later they figure out a way to cache using different strategies. 4) Google At some point google's algorithm to crawl pages become inefficient, it would take 3 weeks to crawl new pages. Google stopped crawling new pages for 6 months & showed only the old crawled pages to users on search. The cool part was users didn't even notice that. 5) Friendster vs MySpace Friendster used to have a feature to show you how far this connection is from you. But this little so-called important functionality was very expensive. It will fire a query for each user-friend multiple times to figure out by going through existing connections to figure out how this person is linked with the current user. This functionality would fire tons of queries & took a lot of time. Myspace used the same feature but instead of finding a connection through multiple queries, they would fire a single query if the person is your friend otherwise they would show text, "this is your far connection" :D Source: Y Combinator Conclusion is, Don't stress too much about scaling before you even start, rather start small & scale with the time.
 Saad Rahman 3 min read
Saad Rahman 3 min read 1. The Ternary Operator Above is the example of a Ternary Operator (?) used as a conditional expression. This shorthand use of the conditional expression is more preferred over the if-else statement for situations where you have to specifically choose between two situations to run some arithematic logic or render something on your page quickly. How this expression basically works is that the condition is checked first, if the condition is true then the statement after the ternary operator ( ? ) will run, and if that’s not the case then the statement after the colon ( : ) will run. 2. Destructuring The JavaScript destruction feature allows you to smoothly assign values or objects in one go on the left side of the assignment operator to variables (as shown in above example). One other example: 3. Spread Operator To put it simple a spread operator takes an iterable and divides it into individual elements into an another array or object. Here’s another example: 4. Array Methods .pop() and .push(): .pop() removes item at the end of an array and .push() adds element at the end of an array: There are some other methods like filter, reduce, sort, includes, find, forEach, splice, concat, shift and unshift and so on. 5. Arrow Functions Helps us to create functions in a more simpler manner: 6. Promises Promises are used just like real human promises which ensure some future result, which means they are an asynchronous event. The promises can either be: Resolved — If it completes it’s function Rejected — If the function it tries to do is not successful Pending — When result of the function is not yet determined The .then() function is used when a promise is either resolved or rejected and it takes two callback functions as parameters, first function runs when promise is resolved and the second is optional and runs when the promise is rejected and not resolved. The .catch() function is used for error handling in promise. 7. The Fetch API The fetch() method starts the process of fetching a resource from a server. The fetch() method returns a Promise that resolves to a Response object. 8. Async/Await Async/Await functionality provides a better and cleaner way to deal with Promises. JavaScript is synchronous in nature and async/await helps us write promise-based functions in such a way as if they were synchronous by stopping the execution of further code until the promise is resolved or rejected. To make it work, you have to first use the async keyword before declaring a function. For example, async function promise() {}. Putting async before a function means that the function will always return a promise. Inside an async function, you can use the keyword await to suspend further execution of code until that promise is resolved or rejected. You can use await only inside of an async function. Now, let’s quickly finish off this section with an example: 9. Import/Export Components In React, you have to render every component you declare in the App.js component. In the above example, we created a component called Component and exported it with our code export default Component. Next, we go to App.js and import the Component with the following code: import Component from './Component'. Took help from here. on freecodecamp.



